
The missing link
A poll finds that priming research might be bad enough to save science
Priming in psychology is one of the least respected areas of research. Psychologists have a very dim view of priming, and yet priming research continues. A recent poll asked psychologists if priming is real and meaningful and only 5% said yes. 5% is in line with belief in ESP among researchers.
Priming is subtle suggestions in a paragraph, or a room, or a question that cause nebulous and just as subtle changes in behavior in someone who experiences them.
Why does this research persist despite it being so unlikely to be real? The answer, like many things, is p-values. Luckily, this poll asks approximately the right question so that we can translate the responses into math and say what p-values mean in terms of what the public understands: whether or not something is true.
To do this, we have to fight through a problem known since the 1920s, that p-values don’t guarantee anything, and even if we use what we’re really talking about, which is effect size, the sizes don’t correspond to “care” or “don’t care.” For example, psychology is undecided as to whether we should care about an effect of 0.1, whether it is important, or random. Gone are the days of effects big enough for grand public demonstration, of dino bones and electromagnetic fields. We don’t have a game show called RESIST. THAT. PRIME!
We can’t demonstrate anything with effect sizes, but we can use two numbers that are unambiguous: the ordinary threshold for publication (p < 0.05), and the acceptable proportion of false findings in the literature, and say that priming research is beyond repair.

The proportion of false findings for all of published science was estimated to be 50%. It’s a number very difficult to estimate science-wide, but we can agree that 50% false positives is bad. The ordinary interpretation of publication thresholds is that false positives occur only about 5% of the time.
For the portion of published findings that are false, let’s assume this interpretation:
5% is reasonable. 50% is terrible.
In a single field with a single distribution of how big the effect probably is, you can control the rate of false discoveries by raising the standards for publication. So how high would the standards have to be in priming to keep the false discovery rate at a reasonable 5% level?
Here’s the distribution implied by the poll, counting only researchers who had an opinion:
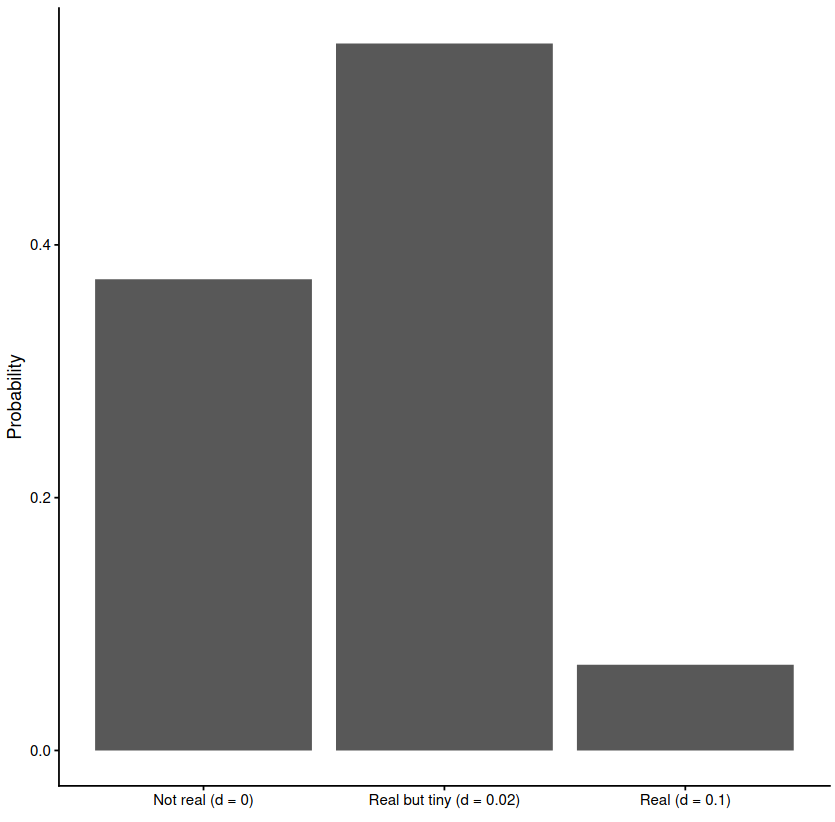
By these estimates, no feasible standard would keep priming research at a reasonable level of false discovery. p-values would have to be lower than 0.001, 50 times stricter than today’s standards.
On the other hand, if you’re fine with 50% of research being false, then anything goes. Even a field as unlikely to be real and meaningful as priming can go on at current standards for publication, or even weaker standards. This is why accepting that half of research is not true is unreasonable, because almost no avenue of inquiry will ever be abandoned.
Worse, if you keep accepting the same standard of evidence, your ESP papers and your priming papers become surprising and “important” because ESP and priming are unlikely to be real.
The power of post hoc
This analysis depends on assumptions like any other and the poll is small. If we want more precise numbers, we should ask for exact estimates instead of buckets like “tiny.” And it assumes sample sizes stay around what they are in psychology. (If you keep p-value standards the same but increase the sample size standard instead, priming studies would cost about 6 times more than they do now.)
Additionally, there are so many researchers who are on the fence in the poll that interpreting “tiny” as 0.02 yields different results compared to 0.1. This is important because effect sizes of 0.1 are called “indispensable” or “crud” depending on who you ask. Despite anchoring to indisputable numbers, we’re back to arguing what “important” means. If respondents on the fence meant tiny is an effect size of 0.1 and the top group meant 0.2, then anything goes and current standards are fine, even for priming.
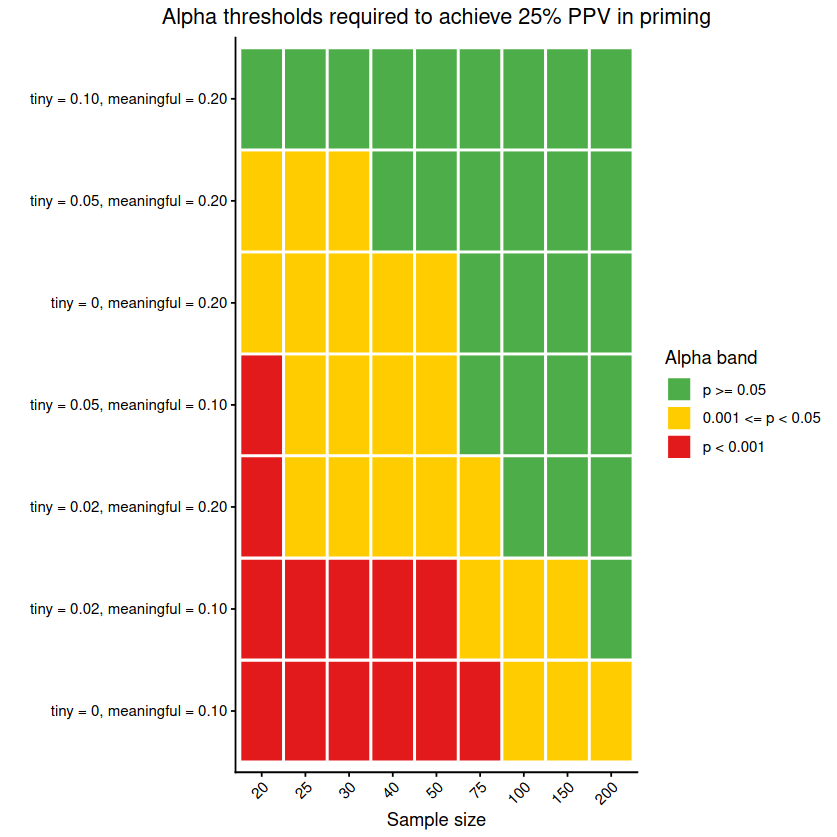
The consequences of being fine with 50% false research should seem eerily similar to the world we live in where anything you’d like to be true can be found in the literature somewhere. It’s also interesting to note that the entire range of implied standards, from open science radical to status quo radical, depends on whether you call 0.1 or 0.02 “tiny.”
So we must all live in awe of the immense power of post hoc reasoning that can change the definition of tiny for the purpose of publication. After the fact, one can simply say 0.1 is important. Findings that many would argue are indistinguishable from noise are suddenly essential building blocks that count in priming’s favor. Journals and researchers are equally innocent on this point since each can blame the other. The only anchor in the epistemic stew is that priming is really one of the worst. There was a replication crisis over it.
Rebuttal
A common rebuttal here is to say that researchers weren’t interpreting the 5% p-value standard as a 5% chance the finding is false. p-value standards don’t guarantee anything, actually. In fact, one could say at this late date that they have always assumed that half of published research is false and p-values are just a convention to weed out completely ridiculous claims. It would be very late as p-values just turned 100.
A journal caught up in a scandal covered by The New Yorker made this move a few weeks ago. They declared that it wasn’t that its case report was not true. All of its case reports aren’t true. They just neglected to say so. Again, we stand in awe of the power of post hoc reasoning. Not saying so in advance truly runs the world.
According to the poll, there really isn’t a compromise among the public, journals, and priming research. One has to go. You can’t tell the public that 50% of what they pay for is false and standards don’t need to go up as a field becomes more implausible. You can’t get journals to agree to 10% because it would mean publishing less and admitting 10% is actually quite strict. Even an optimistic estimate put science-wide falseness at 14%. If you could get the public and journals to agree to something like 10% that is a real stretch for both parties, priming would still be wiped out.
The larger point is that we’re not sure the public would approve of p-values at all. Not without an estimate of what they mean about a field. We also don’t know what reform would make this estimating work, and who does it, but the information we need is in the poll.